字符串的传输与存储之UTF-8
???
一个汉字占多大空间?
百度
IDE Debug

现在,我们得出一个结论:一个汉字占用 2 字节空间。
为什么保存在文本文件中的后会多占用 1 字节?
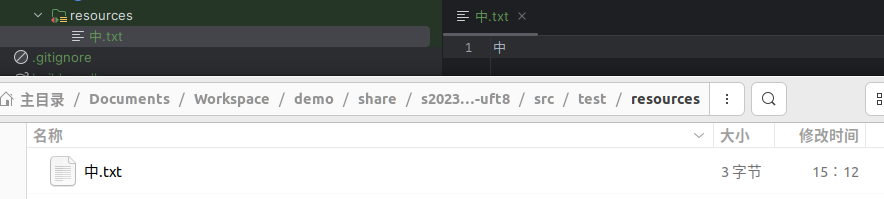
通过文本编辑器写入的文本
通过编程方式写入的文本
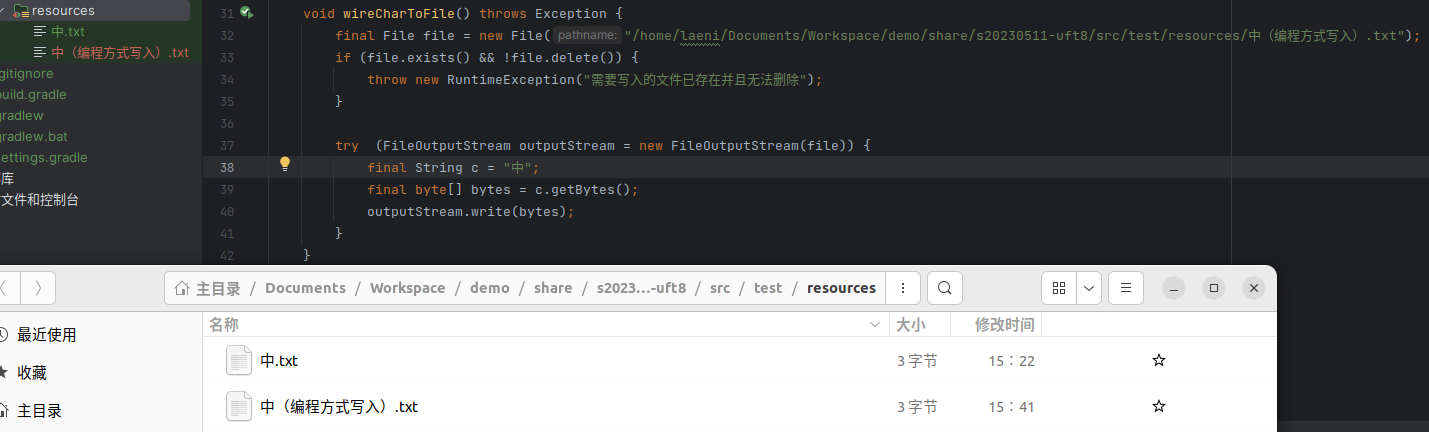
通过不同方式写入的文件结果是一样的,说明多出的 1 字节不是文本编辑器加上去特殊标识,而是汉字转换为字节流之后本身就占用 3 个字节。这可以通过查看实例代码中
bytes变量加以证实。
猜测getBytes()时所使用的编码方式不同将得到不同长度的字节流
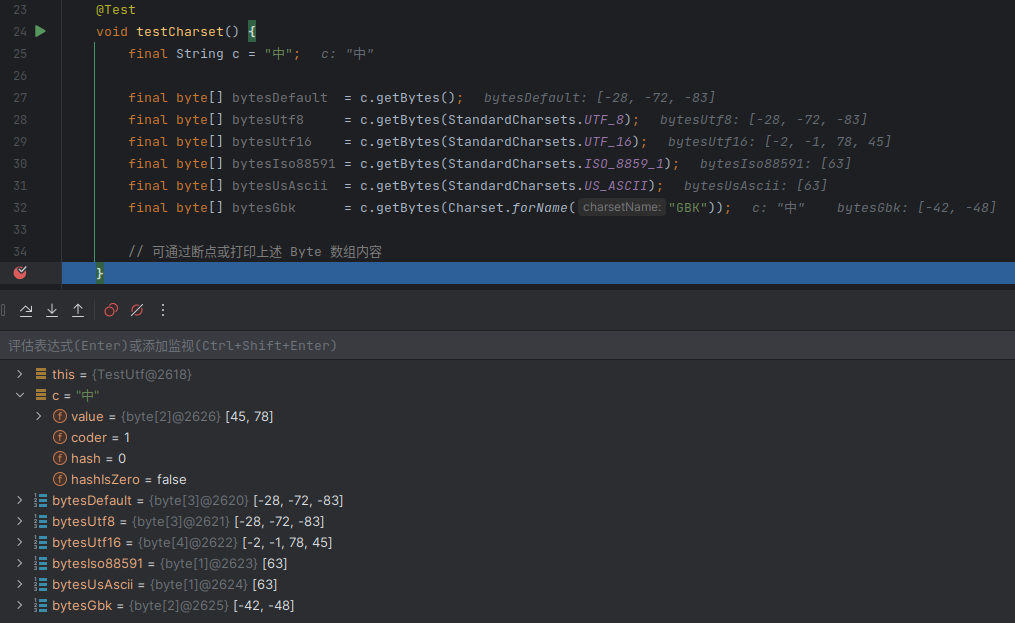
通过以上实验验证了“不同的编码方式将得到的字节流”这一猜想,但同时也发现几个问题:
- 字符串在 Java 内存中是以何种编码存储的?为什么它和
UTF-16有共同点,这是不是巧合? - 既然
GBK占用的空间更小,为什么我们平时不用它,而是选择占用空间更大的UTF-8?
字符串在 Java 内存中如何存储?
A: 查看原码可知,Java String 类中只有两种编码(LATIN1和UTF16),其他任何编码的字节流在转换为 Java 字符串时,都会将其转换为这两种编码的其中一种,具体规则是:如果所有字符全部都在LATIN1范围内,那就用LATIN1编码,否则用UTF16。这样做的原因是,UTF16包含了LATIN1,且LATIN1更省空间,所以优先使用LATIN1。
即使在中国,为什么要选用UTF-8,而不用GBK?
A: 最主要原因是因为GBK字符集虽然在存储中文时占用空间小,但是很多字符并不在它的范围内,而UTF-8这类字符集理论上能表示目前所有的字符。其他更细致原因后面分析,也可以参考UTF-8的由来。
UTF
简介
UTF是“Unicode Transformation Format”的简称,中译为“Unicode 格式转换”。从它的名称看,它并非是字符集,而只是对Unicode字符集的字符按照一定的规则进行转换,以便能更好地进行网络传输或者存储,根据分组编码的位数不同,分为了UTF-8、UTF-16、UTF-32,即对于 UTF-8,应该说“UTF-8 编码”。但是从另外一方面,我们也可以将诸如UTF-8、UTF-16这类编码方式看成是基于 Unicode 字符集的新字符集,所以平时说“UTF-8 字符集“也没问题。
???
- UTF-16 和 UTF-32 是 UTF-8 的升级版吗?它们的区别是什么?
- 我们今天用 UTF-8,后面哪天会不会用 UTF-16?
- 未来会有 UTF-64 吗?
一步一步生成 UTF-8 编码
通过计算机,我们很容易知道字符“中”的 UTF-8 编码为[-28, -73, -83],但是它是怎样得到的?
UTF-8 编码规则
- UTF-8 是对 Unicode 码点二进制进行编码。
- 如果
<Unicode码点二进制位数>小于等于7,该字符的 Unicode 码点即为 UTF-8 编码。 - 否则:
- 设
n为某字符编码之后占用的字节数。 - 第一个字节:前
n位都设为1,第n + 1位设为0。 - 后面字节的前两位一律设为
10,剩下的没有提及的二进制位,全部用这个字符的码点从右往左填充,其他如果还有空为则全部为0。
- 设
根据上述规则,在不考虑 Unicode 容量的情况下,UTF-8 编码后的格式如下表:
| 字符大小 | UTF-8编码格式 | 容量(位) |
|---|---|---|
| 1字节 | 0XXXXXXXX | 1 - 7 |
| 2字节 | 110xxxxx 10xxxxxx | 8 - 11 |
| 3字节 | 1110xxxx 10xxxxxx 10xxxxxx | 12 - 16 |
| 4字节 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 17 - 21 |
| 5字节 | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx | 22 - 26 |
| 6字节 | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx | 27 - 31 |
| 7字节 | 11111110 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx | 32 - 36 |
编码练习
A
-
查询
A的 Unicode 编号:\u41 -
\u41为 16 进制,对应 10 进制为:65。 -
得到编号对应的二进制位:
1000001 -
A字符码点长度小于等于7,所以1000001就是A的 Unicode 码点,即 10 进制65。
中
-
查询
中的 Unicode 编号:\u4e2d -
\u4e2d为 16 进制,对应 10 进制为:20013。 -
得到编号对应的二进制位:
100111000101101 -
中字符码点长度为15,为多字节字符(由上表可知,为3字节字符)。 -
1110xxxx 10xxxxxx 10xxxxxx
100 111000 101101
1110xxxx 10xxxxxx 10xxxxxx
11100100 10111000 10101101
228 184 173
00011100 01001000 01010011
-28 -72 -83
UTF-16
1. 100111000101101
2. 0100111000101101
3. 01001110 00101101
4. 78 45
// UTF-32
00000000000000000100111000101101