Prometheus 快速入门
通常情况下说 Prometheus 可能只是指“Prometheus 指标”或者“Prometheus 告警”,而不是单纯的 Prometheus Server。完整的 Prometheus 是一个由多种组件组成的体系,每种组件都有其特定的应用场景,它们之间的关系如下图所示。
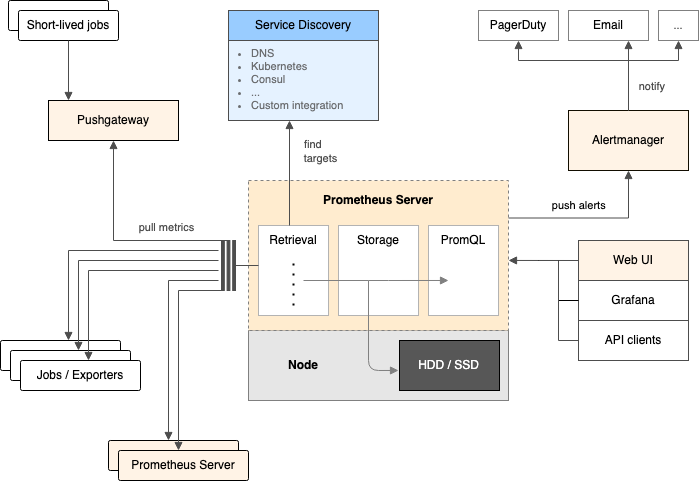
组件功能概览
Prometheus(Server):
- 数据存储: Prometheus 是一个时序数据库(这是其最核心的功能),用于存储指标数据,同时有自己的查询语言(PromQL),用于查询和分析指标数据。
- 指标抓取: Prometheus 会定期抓取被监控实例公开的所有指标数据,抓取后将他们按照时间顺序存储起来。
- 发出告警: Prometheus 会定期执行给定的规则,规则一般通过 PromQL 查询数据,并在满足规则中定义的条件时向 Alertmanager 发出告警(每次评估规则时,只要满足告警条件就会发送告警)。
Alertmanager:
Prometheus 只管根据指标以及告警条件发出告警,之后由 Alertmanager 组件来管理这些告警。
- 警告通知: 将告警信息发送给告警接收人。
- 告警抑制: 一般情况下,Prometheus 会持续发送告警,但是 Alertmanager 并不会每次受到告警都将告警发送给告警接收人,因为此告警可能已经通知过了。
- 告警恢复: 如果 Alertmanager 持续一段时间没有再受到 Prometheus 的告警信息,则 Alertmanager 就认为对应告警已经恢复。
UI:
UI 是指 WEB UI 或 Prometheus API 客户端,通过他们可以以可视化的方式和 Prometheus 进行交互。
PushGateway:
正常情况下,Prometheus 都是采用定期主动抓取的方式,但是有些场景不能使用这种方式,比如存在周期很短的云函数等。在这种情况下就不能直接通过 Prometheus 直接去抓取,以云函数为例,可以让函数运行期间将其相关的指标信息主动推送到 PushGateway,这样,当 Prometheus 去抓取 PushGateway 的时候就能拿到云函数的相关指标。
PushProx:
当 Prometheus 和被抓取的目标位于两个隔离的网络时,如果能从目标网络访问到 Prometheus 网络,但是不能从 Prometheus 网络访问到目标网络时(典型案例是:Prometheus 位于公网,而被抓取目标位于内网),官方提供的一个解决方案。通过 PushProx,可以让 Prometheus 访问到防火墙后的目标实例,从而实现主动抓取行为。实际使用中不一定要通过这种方式,只要能让 Prometheus 能抓取到目标指标即可。
Service Discovery:
Service Discovery(服务发现)并不是 Prometheus 项目的组件,而只是让 Prometheus 自动发现被抓取目标的方式之一。Prometheus 支持多种方式的服务发现。
Prometheus
安装
cat > prometheus.yml <<EOF
# my global config
global:
scrape_interval: 15s # 将抓取间隔设置为每 15 秒。默认为每 1 分钟。
evaluation_interval: 15s # 每 15 秒评估一次规则。默认值为每 1 分钟。
# scrape_timeout 设置为全局默认值 (10s)。
# 与外部系统(联合、远程存储、Alertmanager)通信时将这些标签附加到任何时间序列或警报。
external_labels:
monitor: 'codelab-monitor'
# Alertmanager 配置
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# 加载规则一次并根据全局“evaluation_interval”定期对其进行评估。
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# 一个抓取配置只包含一个要抓取的端点
scrape_configs:
# 里是 Prometheus 本身。
# 作业名称作为标签`job=<job_name>`添加到从此配置中抓取的任何时间序列。
- job_name: "prometheus"
# metrics_path 默认为 '/metrics'
# scheme 默认为 'http'.
static_configs:
- targets: ["localhost:9090"]
EOF
PWD=$(dirname $(readlink -f "$0"))
docker run -d \
--restart=always \
--name prometheus \
-p 9090:9090 \
-v /etc/localtime:/etc/localtime \
-v ${PWD}/prometheus:/prometheus `# 数据存储目录` \
-v ${PWD}/prometheus.yml:/etc/prometheus/prometheus.yml `# 配置文件` \
prom/prometheus:v2.45.6
上述命令将使用默认配置(部分配置来源于官网开始使用)启动服务端,并将自己加入监控。
使用
安装后可通过http://localhost:9090/graph进入控制台。
有关表达式语言的详细信息,请参阅表达式语言文档。
发现
Prometheus 提供了多种服务发现选项来发现抓取目标,包括 Kubernetes、Consul 和基于文件的服务发现等。
示例
基于文件的服务发现
prometheus.yml:
scrape_configs:
- job_name: 'node'
file_sd_configs:
- files:
- 'targets.json'
targets.json:
[
{ "targets": ["localhost:9100"], "labels": { "job": "node" } },
{ "targets": ["localhost:9101"], "labels": { "job": "node" } }
]
在 Spring Actuator 中添加 prometheus 端点提供指标服务
Spring Boot 配置
pom.xml:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
application.yml:
server:
port: 8080
servlet:
context-path: /project-name
management:
endpoints:
web:
exposure:
include:
- prometheus # 公开 Prometheus 指标
metrics:
tags:
application: ${spring.application.name}
现在可以通过
/project-name/actuator/prometheus访问公开的指标。
统计 Controller:
@RestController
@io.micrometer.core.annotation.Timed(value = "http_api_request_duration", description = "接口响应时间", histogram = true)
public class Controller {}
手动统计Counter 指标:
public class MyClass {
private final Counter counter;
public MyClass(MeterRegistry registry) {
// 创建指标实例
this.counter = Counter
.builder("http_api_request_count")
.description("HTTP 接口总请求次数")
.tags("tag-1", "value-1", "tag-2", "value-2")
.register(registry);
}
public void run() {
// 增加指标计数
this.counter.increment();
}
}
Prometheus 配置
由于指标路径不是常见的 /metrics 格式,而是 /project-name/actuator/prometheus 格式(前缀根据项目的不同而不同),所以指标路径需要动态生成。
假设自动发现文件为 sd-node.json:
[
{
"targets": ["10.10.1.3:8081"],
"labels": { "project":"my-project" }
}
]
即根据project标签来标识项目名,则 prometheus.yml 中关于自动发现部分的配置为:
scrape_configs:
- job_name: spring-actuators
# 由于抓取路径随项目变化而变化,所以动态生成(使用自动发现文件配置的属性来生成)
relabel_configs:
# 此配置的含义: 使用正则匹配输入数据('source_labels: [project]'),匹配后按'replacement'的规则进行替换,并将替换后的内容写入'__metrics_path__'标签
# 1. `__metrics_path__`为实际指标抓取是使用的路径(不含主机部分);2. `project` 为自动发现文件`conf.d/sd-ibox-spring-dev.json` 中配置的自定义标签;3. 所有可用的标签可以通过`/service-discovery`页面查看
- source_labels: [project]
regex: '(.*)'
target_label: __metrics_path__
replacement: '/$1/actuator/prometheus'
# 使用文件来发现抓取目标 - https://prometheus.io/docs/guides/file-sd/
file_sd_configs:
- files: ['sd-node.json']
refresh_interval: 30s
如果没有
context-path,则直接通过metrics_path: /actuator/prometheus配置即可。
指标类型
counter(计数器)
在 Prometheus 中,计数器是一种单调递增的指标(即该值不能比前一个值减少,但可以重置),通常用于统计某个事件发生的次数。例如:
- HTTP 请求的总次数
- 错误的发生次数
- 系统启动以来的运行时间
计数器通常配合rate函数使用。
gauge(仪表/度量)
仪表是一个可以上升或下降的数字。它可以用于衡量指标,如集群中的 Pod 数量、队列中的事件数量等。
PromQL 函数,如 max_over_time、 min_over_time 和 avg_over_time 可用于仪表指标。
histogram(直方图)
直方图可用于任何可计算的值,这些值根据桶值进行计数。存储桶边界可由开发人员配置。一个常见的示例是回复请求所需的时间,称为延迟。
示例:假设我们想要观察处理 API 请求所花费的时间。
直方图不是存储每个请求的请求时间,而是允许我们将它们存储在存储桶中。例如,我们为所花费的时间定义存储桶 lower or equal 0.3、 le 0.5、 le 0.7、 le 1和 le 1.2。因此,这些是我们的存储桶,一旦计算出请求所花费的时间,它就会被添加到存储桶边界高于测量值的所有存储桶的计数中。
假设第一次请求“/ping”端点时耗时 0.25 秒,则存储桶的计数值将为:
| 桶 | 计数 |
|---|---|
| 0 - 0.3 | 1 |
| 0 - 0.5 | 1 |
| 0 - 0.7 | 1 |
| 0 - 1 | 1 |
| 0 - 1.2 | 1 |
| 0 - +Inf | 1 |
注意:默认情况下会添加 +Inf 存储桶。
假设第二次请求“/ping”端点时耗时 0.4 秒,则存储桶的计数值将为。
| 桶 | 计数 |
|---|---|
| 0 - 0.3 | 1 |
| 0 - 0.5 | 2 |
| 0 - 0.7 | 2 |
| 0 - 1 | 2 |
| 0 - 1.2 | 2 |
| 0 - +Inf | 2 |
由于 0.4 低于 0.5,因此达到该边界的所有桶都会增加其计数。
计数器通常配合histogram_quantile函数使用。
summary(总和)
总和还可以测量事件,并且是直方图的替代方法。它们更轻量级,但会丢失更多数据。它们是在应用程序级别计算的,因此无法聚合来自同一进程的多个实例的指标。当事先不知道指标的存储桶时,会使用直方图,但强烈建议尽可能使用直方图而不是总和。
PromQL
PromQL (Prometheus Query Language) 是 Prometheus 自己开发的数据查询 DSL 语言,语言表现力非常丰富,内置函数很多,在日常数据可视化以及rule 告警中都会使用到它。
当向 Prometheus 发送一个查询请求时,可以是即时查询(在某个时间点进行评估),也可以是在起始时间和结束时间之间按等间隔步长进行的区间查询。PromQL 在这两种情况下工作方式完全相同;区间查询就像是在不同时间戳上多次运行的即时查询。在 Prometheus 的用户界面中,“Table”标签页用于即时查询,而“Graph”标签页用于区间查询。其他程序可以通过 HTTP API 获取 PromQL 表达式的结果。
在页面 http://localhost:9090/graph 中,输入下面的查询语句,查看结果,例如:
http_requests_total{code="200"}
表达式语言的数据类型
在Prometheus的表达式语言中,一个表达式或子表达式可以计算出以下四种类型之一:
- 瞬时向量(Instant vector): 一组时间序列,每个时间序列包含一个样本,且所有样本具有相同的时间戳
- 范围向量(Range vector): 一组时间序列,每个时间序列包含一段时间范围内的多个数据点
- 标量(Scalar): 一个简单的数值型浮点值
- 字符串(String): 一个简单的字符串值;当前未被使用
根据使用情况(例如,当绘图与显示表达式输出时),这些类型中只有一些可以合法地作为用户指定表达式的结果。对于瞬时查询,上述任何数据类型都可以作为表达式的根类型。范围查询仅支持标量类型和瞬时向量类型的表达式。
字面量
字符串字面量
字符串字面量使用单引号、双引号或反引号来表示。PromQL 的转义规则与 Go 相同。对于使用单引号或双引号的字符串字面量,反斜杠开始一个转义序列,可以后跟 a、b、f、n、r、t、v 或 \。可以使用八进制(\nnn)或十六进制(\xnn、\unnnn 和 \Unnnnnnnn)表示法来指定特定字符。相反,使用反引号表示的字符串字面量中不会解析转义字符。需要注意的是,与 Go 不同,Prometheus 不会忽略反引号内的换行符。
示例:
"this is a string"
'these are unescaped: \n \\ \t'
`these are not unescaped: \n ' " \t`
数字和时间范围
标量浮点数值可以采用如下格式以整数字面量或浮点数字面量的形式书写(此处的空白仅为提高可读性):
[-+]?(
[0-9]*\.?[0-9]+([eE][-+]?[0-9]+)?
| 0[xX][0-9a-fA-F]+
| [nN][aA][nN]
| [iI][nN][fF]
)
示例:
23
-2.43
3.4e-9
0x8f
-Inf
NaN
此外,下划线(_)可以用于十进制或十六进制数字之间,以提高可读性。
示例:
1_000_000
.123_456_789
0x_53_AB_F3_82
浮点字面量也可用于以秒为单位指定持续时间。为了方便起见,十进制整数可以与以下时间单位结合使用:
ms– 毫秒s– 秒 – 1秒等于1000毫秒m– 分钟 – 1分钟等于60秒(忽略闰秒)h– 小时 – 1小时等于60分钟d– 天 – 1天等于24小时(忽略所谓的夏令时)w– 周 – 1周等于7天y– 年 – 1年等于365天(忽略闰年)
在十进制整数后附加上述单位之一,是对相当于该整数的秒数的另一种表示方式,这种表示方式等同于直接使用浮点字面量。
示例:
1s # 相当于 1.
2m # 相当于 120.
1ms # 相当于 0.001.
-2h # 相当于 -7200.
以下示例无法使用:
0xABm # 不要在十六进制数后添加后缀。
1.5h # 时间单位不能与浮点数结合使用。
+Infd # 不要在 ±Inf NaN 后添加后缀。
多个单位可以通过后缀整数的连接组合在一起。单位必须从最长到最短排序。每个浮点字面量中,同一单位只能出现一次。
示例:
1h30m # 相当于 5400s,即 5400。
12h34m56s # 相当于 45296s,即 45296.
54s321ms # 相当于 54.321.
时间序列选择器
这些是指导 PromQL 获取哪些数据的基本构建模块。
Instant vector selectors
Instant vector selectors allow the selection of a set of time series and a single sample value for each at a given timestamp (point in time). In the simplest form, only a metric name is specified, which results in an instant vector containing elements for all time series that have this metric name.
The value returned will be that of the most recent sample at or before the query's evaluation timestamp (in the case of an instant query) or the current step within the query (in the case of a range query). The @ modifier allows overriding the timestamp relative to which the selection takes place. Time series are only returned if their most recent sample is less than the lookback period ago.
This example selects all time series that have the http_requests_total metric name, returning the most recent sample for each:
http_requests_total
It is possible to filter these time series further by appending a comma-separated list of label matchers in curly braces ({}).
This example selects only those time series with the http_requests_total metric name that also have the job label set to prometheus and their group label set to canary:
http_requests_total{job="prometheus",group="canary"}
It is also possible to negatively match a label value, or to match label values against regular expressions. The following label matching operators exist:
=: Select labels that are exactly equal to the provided string.!=: Select labels that are not equal to the provided string.=~: Select labels that regex-match the provided string.!~: Select labels that do not regex-match the provided string.
Regex matches are fully anchored. A match of env=~"foo" is treated as env=~"^foo$".
For example, this selects all http_requests_total time series for staging, testing, and development environments and HTTP methods other than GET.
http_requests_total{environment=~"staging|testing|development",method!="GET"}
Label matchers that match empty label values also select all time series that do not have the specific label set at all. It is possible to have multiple matchers for the same label name.
For example, given the dataset:
http_requests_total
http_requests_total{replica="rep-a"}
http_requests_total{replica="rep-b"}
http_requests_total{environment="development"}
The query http_requests_total{environment=""} would match and return:
http_requests_total
http_requests_total{replica="rep-a"}
http_requests_total{replica="rep-b"}
and would exclude:
http_requests_total{environment="development"}
Multiple matchers can be used for the same label name; they all must pass for a result to be returned.
The query:
http_requests_total{replica!="rep-a",replica=~"rep.*"}
Would then match:
http_requests_total{replica="rep-b"}
Vector selectors must either specify a name or at least one label matcher that does not match the empty string. The following expression is illegal:
{job=~".*"} # Bad!
In contrast, these expressions are valid as they both have a selector that does not match empty label values.
{job=~".+"} # Good!
{job=~".*",method="get"} # Good!
Label matchers can also be applied to metric names by matching against the internal __name__ label. For example, the expression http_requests_total is equivalent to {__name__="http_requests_total"}. Matchers other than = (!=, =~, !~) may also be used. The following expression selects all metrics that have a name starting with job::
{__name__=~"job:.*"}
The metric name must not be one of the keywords bool, on, ignoring, group_left and group_right. The following expression is illegal:
on{} # Bad!
A workaround for this restriction is to use the __name__ label:
{__name__="on"} # Good!
Range Vector Selectors
Range vector literals work like instant vector literals, except that they select a range of samples back from the current instant. Syntactically, a float literal is appended in square brackets ([]) at the end of a vector selector to specify for how many seconds back in time values should be fetched for each resulting range vector element. Commonly, the float literal uses the syntax with one or more time units, e.g. [5m]. The range is a left-open and right-closed interval, i.e. samples with timestamps coinciding with the left boundary of the range are excluded from the selection, while samples coinciding with the right boundary of the range are included in the selection.
In this example, we select all the values recorded less than 5m ago for all time series that have the metric name http_requests_total and a job label set to prometheus:
http_requests_total{job="prometheus"}[5m]
Offset modifier
The offset modifier allows changing the time offset for individual instant and range vectors in a query.
For example, the following expression returns the value of http_requests_total 5 minutes in the past relative to the current query evaluation time:
http_requests_total offset 5m
Note that the offset modifier always needs to follow the selector immediately, i.e. the following would be correct:
sum(http_requests_total{method="GET"} offset 5m) // GOOD.
While the following would be incorrect:
sum(http_requests_total{method="GET"}) offset 5m // INVALID.
The same works for range vectors. This returns the 5-minute rate that http_requests_total had a week ago:
rate(http_requests_total[5m] offset 1w)
When querying for samples in the past, a negative offset will enable temporal comparisons forward in time:
rate(http_requests_total[5m] offset -1w)
Note that this allows a query to look ahead of its evaluation time.
@ modifier
The @ modifier allows changing the evaluation time for individual instant and range vectors in a query. The time supplied to the @ modifier is a unix timestamp and described with a float literal.
For example, the following expression returns the value of http_requests_total at 2021-01-04T07:40:00+00:00:
http_requests_total @ 1609746000
Note that the @ modifier always needs to follow the selector immediately, i.e. the following would be correct:
sum(http_requests_total{method="GET"} @ 1609746000) // GOOD.
While the following would be incorrect:
sum(http_requests_total{method="GET"}) @ 1609746000 // INVALID.
The same works for range vectors. This returns the 5-minute rate that http_requests_total had at 2021-01-04T07:40:00+00:00:
rate(http_requests_total[5m] @ 1609746000)
The @ modifier supports all representations of numeric literals described above. It works with the offset modifier where the offset is applied relative to the @ modifier time. The results are the same irrespective of the order of the modifiers.
For example, these two queries will produce the same result:
# offset after @
http_requests_total @ 1609746000 offset 5m
# offset before @
http_requests_total offset 5m @ 1609746000
Additionally, start() and end() can also be used as values for the @ modifier as special values.
For a range query, they resolve to the start and end of the range query respectively and remain the same for all steps.
For an instant query, start() and end() both resolve to the evaluation time.
http_requests_total @ start()
rate(http_requests_total[5m] @ end())
Note that the @ modifier allows a query to look ahead of its evaluation time.
Subquery
Subquery allows you to run an instant query for a given range and resolution. The result of a subquery is a range vector.
Syntax: <instant_query> '[' <range> ':' [<resolution>] ']' [ @ <float_literal> ] [ offset <float_literal> ]
<resolution>is optional. Default is the global evaluation interval.
Operators
Prometheus supports many binary and aggregation operators. These are described in detail in the expression language operators page.
函数
某些函数具有默认参数,例如:year(v=vector(time()) instant-vector)。这意味着参数 v 是一个即时向量,如果没有提供该参数,则会默认使用表达式 vector(time()) 的值。
// TODO
聚合函数 - count,sum,avg,max,min
语法:
funName [by (label1, label2, ...)] (your_metric)
其他函数
Prometheus 内置不少函数,方便查询以及数据格式化,例如将结果由浮点数转为整数的 floor 和 ceil,
floor(avg(http_requests_total{code="200"}))
ceil(avg(http_requests_total{code="200"}))
查看 http_requests_total 5分钟内,平均每秒数据
rate(http_requests_total[5m])
更多请参见详情。
rate
rate 函数主要用于 计算一个计数器在一段时间内的平均增长率。它在监控系统中被广泛用于计算每秒请求数、每秒错误数等指标。
rate 函数通过比较一段时间内计数器的值的变化来计算增长率。它可以帮助我们回答以下问题:
- 系统当前的负载如何? 通过计算每秒请求数,我们可以了解系统当前承受的压力。
- 系统性能是否稳定? 通过观察每秒错误数的趋势,我们可以判断系统是否出现了问题。
- 系统资源是否充足? 通过计算资源使用量的增长率,我们可以预测系统是否会很快耗尽资源。
函数语法
rate(v[d])
- v: 一个计数器指标。
- d: 时间间隔,例如
5m、1h等。
示例
rate(go_gc_duration_seconds_count[5m])
注意事项
- 计数器重置: rate 函数假设计数器不会被重置。如果计数器被重置,计算结果将不准确。
- 时间间隔: 选择合适的时间间隔非常重要。太短的时间间隔可能导致结果波动较大,太长的时间间隔可能掩盖短期内的变化。
- 采样率: rate 函数的计算结果与 Prometheus 的采样率有关。采样率越高,计算结果越精确。
常见应用场景
- 计算每秒请求数 (QPS): 监控系统负载。
- 计算错误率: 评估系统稳定性。
- 计算资源使用率: 预测系统容量。
- 检测异常: 发现系统中的异常行为。
histogram_quantile
histogram_quantile 主要用于 计算直方图指标的分位数。它在监控系统中被广泛用于计算延迟、请求大小等指标的分位数,从而更深入地了解系统的性能分布。
函数语法
histogram_quantile(φ, histogram)
- φ: 要计算的分位数,是一个介于 0 和 1 之间的浮点数。例如,0.95 表示计算第 95 个百分位数。
- histogram: 一个直方图指标。
示例
假设我们有一个名为 http_request_duration_seconds 的直方图指标,用于统计 HTTP 请求的耗时。我们可以使用以下查询来计算最近 5 分钟内请求耗时的第 99 个百分位数:
histogram_quantile(0.99, rate(http_request_duration_seconds[5m]))
函数的工作原理
histogram_quantile 函数通过以下步骤计算分位数:
- 找到包含目标分位数的桶: 函数会找到一个桶,使得该桶以及所有小于该桶的桶中的数据点之和大于或等于目标分位数所对应的数据点数量。
- 线性插值: 如果目标分位数落在两个桶之间,函数会使用线性插值的方法来计算精确的分位数值。
使用场景
- 计算服务延迟: 计算请求处理时间的 P95、P99 等分位数,以了解服务的性能瓶颈。
- 分析请求大小分布: 计算请求大小的分位数,以优化资源分配。
- 监控错误率: 计算错误请求比例,以了解系统的稳定性。
注意事项
- 直方图数据: 确保你的指标是直方图类型,并且具有正确的桶边界。
- 分位数范围: 分位数的值必须在 0 和 1 之间。
- 线性插值假设:
histogram_quantile函数假设桶内的数据分布是线性的,这可能导致计算结果与实际值存在一定的误差。 - rate 函数: 在计算分位数之前,通常会使用
rate函数来计算一段时间内的平均增长率,以获得更准确的结果。
聚合函数
Comments
PromQL supports line comments that start with #. Example:
# This is a comment
Regular expressions
All regular expressions in Prometheus use RE2 syntax.
Regex matches are always fully anchored.
Gotchas
Staleness
The timestamps at which to sample data, during a query, are selected independently of the actual present time series data. This is mainly to support cases like aggregation (sum, avg, and so on), where multiple aggregated time series do not precisely align in time. Because of their independence, Prometheus needs to assign a value at those timestamps for each relevant time series. It does so by taking the newest sample that is less than the lookback period ago. The lookback period is 5 minutes by default, but can be set with the --query.lookback-delta flag
If a target scrape or rule evaluation no longer returns a sample for a time series that was previously present, this time series will be marked as stale. If a target is removed, the previously retrieved time series will be marked as stale soon after removal.
If a query is evaluated at a sampling timestamp after a time series is marked as stale, then no value is returned for that time series. If new samples are subsequently ingested for that time series, they will be returned as expected.
A time series will go stale when it is no longer exported, or the target no longer exists. Such time series will disappear from graphs at the times of their latest collected sample, and they will not be returned in queries after they are marked stale.
Some exporters, which put their own timestamps on samples, get a different behaviour: series that stop being exported take the last value for (by default) 5 minutes before disappearing. The track_timestamps_staleness setting can change this.
Avoiding slow queries and overloads
If a query needs to operate on a substantial amount of data, graphing it might time out or overload the server or browser. Thus, when constructing queries over unknown data, always start building the query in the tabular view of Prometheus's expression browser until the result set seems reasonable (hundreds, not thousands, of time series at most). Only when you have filtered or aggregated your data sufficiently, switch to graph mode. If the expression still takes too long to graph ad-hoc, pre-record it via a recording rule.
This is especially relevant for Prometheus's query language, where a bare metric name selector like api_http_requests_total could expand to thousands of time series with different labels. Also, keep in mind that expressions that aggregate over many time series will generate load on the server even if the output is only a small number of time series. This is similar to how it would be slow to sum all values of a column in a relational database, even if the output value is only a single number.
查询条件
Prometheus 存储的是时序数据,而它的时序是由名称和一组标签构成的,其实名字也可以写成标签的形式,例如 http_requests_total 等价于 {name="http_requests_total"}。
一个简单的查询相当于是对各种标签的筛选,例如:
http_requests_total{code="200"} // 表示查询名称为 http_requests_total,code 标签为 "200" 的数据
查询条件支持正则匹配,例如:
http_requests_total{code!="200"} // 表示查询 code 不为 "200" 的数据
http_requests_total{code=~"2.."} // 表示查询 code 为 "2xx" 的数据
http_requests_total{code!~"2.."} // 表示查询 code 不为 "2xx" 的数据
操作符
Prometheus 查询语句中,支持常见的各种表达式操作符,例如
算术运算符:
支持的算术运算符有 +,-,*,/,%,^, 例如 http_requests_total * 2 表示将 http_requests_total 所有数据 double 一倍。
比较运算符:
支持的比较运算符有 ==,!=,>,<,>=,<=, 例如 http_requests_total > 100 表示 http_requests_total 结果中大于 100 的数据。
逻辑运算符:
支持的逻辑运算符有 and,or,unless, 例如 http_requests_total == 5 or http_requests_total == 2 表示 http_requests_total 结果中等于 5 或者 2 的数据。
聚合运算符:
支持的聚合运算符有 sum,min,max,avg,stddev,stdvar,count,count_values,bottomk,topk,quantile,, 例如 max(http_requests_total) 表示 http_requests_total 结果中最大的数据。
注意,和四则运算类型,Prometheus 的运算符也有优先级,它们遵从(^)> (*, /, %) > (+, -) > (==, !=, <=, <, >=, >) > (and, unless) > (or) 的原则。
常见问题
- 为什么我计算的 P99 值总是比预期的要高?
- 这可能是因为你的桶边界设置不合理,导致数据点集中在几个桶中。
- 也可以是因为你的样本数量不够多,导致统计结果不够准确。
- 如何选择合适的桶边界?
- 桶边界的选择取决于你想要分析的数据的分布情况。一般来说,对于长尾分布的数据,需要设置更多的桶边界。
常用 PromQL
磁盘相关
-
查询剩余空间
node_filesystem_free_bytes{job="node-hx", fstype=~"xfs|ext4", mountpoint!~"/boot.*"} -
查询总空间
node_filesystem_size_bytes{job="node-hx", fstype=~"xfs|ext4", mountpoint!~"/boot.*"} -
查询已用空间百分比
// (1 - 剩余空间 / 总空间) * 100 (1 - node_filesystem_free_bytes{job="node-hx", fstype=~"xfs|ext4", mountpoint!~"/boot.*"} / node_filesystem_size_bytes{job="node-hx", fstype=~"xfs|ext4", mountpoint!~"/boot.*"}) * 100
PushProx
PushProx 是一个客户端和代理,用于解决 Prometheus 无法直接对抓取位于 NAT 后面的监控实例问题(即只能能从一端访问另一端,如果双方都不不能相互访问时不使用使用此种方式)。

使用
服务端
服务端运行环境需要能被 Prometheus 访问,同时也需要能被 客户端访问(通常和 Prometheus 在一起)。
./pushprox-proxy
服务端默认监听
8080端口.
客户端
./pushprox-client --proxy-url=http://proxy:8080/ --fqdn=<clientName>
常用参数:
--proxy-url: 服务端地址。
--fqdn: 客户端名称。可选,如果缺省则会使用客户端主机名,该名称用于 Prometheus 抓取时指定的客户端
Host。
Prometheus 使用
scrape_configs:
- job_name: node
proxy_url: http://proxy:8080/
static_configs:
- targets: ['<clientName>:9100']
抓取时使用
proxy_url指定代理服务器地址,同时抓取的目标中使用代理客户端fqdn的名称作为目标Host。
Alertmanager
使用 Prometheus 发出警报分为两部分。中的警报规则 Prometheus 服务器向 Alertmanager 发送警报。警报 管理器 然后管理这些警报,包括静音、抑制、聚合和 通过电子邮件、待命通知系统和聊天平台等方式发送通知。
设置警报和通知的主要步骤是:
- 设置和 配置 Alertmanager
- 配置 Prometheus 以与 Alertmanager 通信
- 告警规则 在 Prometheus 中创建
See. https://prometheus.io/docs/alerting/latest/overview/
See. https://prometheus.io/docs/alerting/latest/configuration
接收器
即告警通知接收人,可以是 webhook、邮件、短信等。
WebHook
示例:
global:
resolve_timeout: 5m
route:
receiver: webhook_receiver
receivers: # 可以定义多个接收者
- name: webhook_receiver # 接收者名称,名称可以随意
webhook_configs:
- url: 'https://webhook.site/2c6de686-efd7-4f8e-9e8f-7838f36a9b25' # 当告警产生后,将相关信息发送到该 URL
send_resolved: false # 当恢复后是否发送恢复通知
Alloy
安装
官方文档: https://grafana.com/docs/alloy/latest/set-up/install/.
MacOS
# 添加 Grafana Homebrew 源:
brew tap grafana/grafana
# 安装 Alloy
brew install grafana/grafana/alloy
启动
将 Alloy 作为后台守护进程运行:
brew services start alloy
但是在 MacOS 中,有些功能需要使用 root 权限运行,并且通常只在需要的时候启动,即按需启动:
sudo $(brew --prefix)/opt/alloy/bin/alloy-wrapper
默认情况下,日志写入到
$(brew --prefix)/var/log/alloy.log和$(brew --prefix)/var/log/alloy.err.log。默认配置文件为:
$(brew --prefix)/etc/alloy/config.alloy
Docker
services:
alloy:
image: grafana/alloy:v1.9.1
container_name: alloy
restart: unless-stopped
networks:
- docker
ports:
- 12345:12345
volumes:
- /etc/localtime:/etc/localtime:ro
- /data/docker/alloy:/var/lib/alloy/data:rw
- ./alloy-config.alloy:/etc/alloy/config.alloy:ro
command:
- run
- --server.http.listen-addr=0.0.0.0:12345
- --storage.path=/var/lib/alloy/data
- /etc/alloy/config.alloy
Pyroscope
安装
Java
详情可参考官方文档。
SDK 集成
-
添加依赖
<dependency> <groupId>io.pyroscope</groupId> <artifactId>agent</artifactId> <version>2.1.2</version> </dependency> -
启动
final HashMap<String, String> tags = new HashMap<>(); tags.put("hostname", InetAddress.getLocalHost().getHostName()); tags.put("ip", InetAddress.getLocalHost().getHostAddress()); tags.put("user", System.getProperty("user.name")); tags.put("java_version", System.getProperty("java.version")); tags.put("os", System.getProperty("os.name") + "-" + System.getProperty("os.arch")); tags.put("app_env", System.getProperty("spring.profiles.active", "default")); final Config.Builder builder = new Config.Builder() // 应用标识 .setApplicationName("omms-oms-openplatform-cloud") // 采样方式:ITIMER 适合 CPU 分析 .setProfilingEvent(EventType.ITIMER) // 服务地址(Pyroscope server 或 Grafana Pyroscope) .setServerAddress("http://localhost:4040") // 上传间隔,默认 10s,可调大避免压力 .setUploadInterval(Duration.ofSeconds(15)) // 采样间隔,默认 10ms(越小越精细,开销也越大) .setProfilingInterval(Duration.ofMillis(10)) // 允许追踪存活对象(可帮助排查内存泄漏) .setAllocLive(true) // 限制最大 Java 栈深度(避免 profile 过大) .setJavaStackDepthMax(512) // 上传时是否先触发 GC(方便内存分析) .setGcBeforeDump(false) // 日志等级 .setLogLevel(Logger.Level.DEBUG) // 标签,用于区分实例 .setLabels(tags); // 启动采集 PyroscopeAgent.start(builder.build());
javaagent
export PYROSCOPE_APPLICATION_NAME=my.java.app
export PYROSCOPE_SERVER_ADDRESS=http://pyroscope-server:4040
java -javaagent:pyroscope.jar -jar app.jar
工件可在发布页面或Maven仓库中找到。
Grafana
一. 概述
1.1 Grafana介绍
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。它主要有以下六大特点:
- 展示方式: 快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
- 数据源: Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等;
- 通知提醒: 以可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过Slack、PagerDuty等获得通知;
- 混合展示: 在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
- 注释: 使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记;
- 过滤器: Ad-hoc过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询。
简单来讲,它是一个多用途的监控工具,同时通过邮件等方式进行有效的预警通知,丰富的直观的可视化界面,多种数据源配置是其优点所在;
1.2 Grafana结构图
相关文档
OpenMetrics
OpenMetrics,是云原生、高度可扩展的指标协议。 OpenMetrics 定义了大规模上报云原生指标的事实标准,并支持文本表示协议和 Protocol Buffers 协议。
Micrometer指标类型
| Micrometer指标类型 | 典型用途 |
|---|---|
| Counter | 计数器,单调递增场景。例如,统计 PV 和 UV,接口调用次数等。 |
| Gauge | 持续波动的变量。例如,资源使用率、系统负载、请求队列长度等。 |
| Timer | 统计数据分布。例如,统计某接口调用延时的 P50、P90、P99 等。有的实现叫做 Histogram。 |
| DistributionSummary | 统计数据分布,与 Histogram 用途类似。有的实现叫做 Summary。 |